


CPO赛道对决! Nvidia 和 Broadcom 到底在竞争什么?
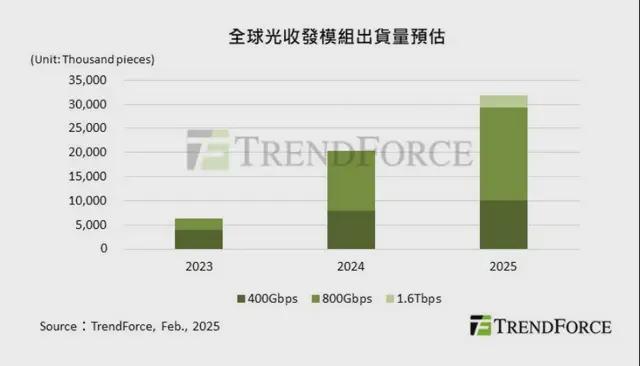 文章|能够率先突破交付和延迟效率极限的半导体行业内部人士,将有机会引领下一波人工智能竞争浪潮。在人工智能(AI)和机器研究的推动下,全球数据流量急剧增加。目前,数据中心服务器和交换机之间的连接正在从200G、400G快速走向800G、1.6T,甚至还可以进入3.2T时代。市场研究机构预测,2023年400G以上光收发模块全球传输量为640万台,2024年约为2040万台,预计2025年将超过3190万台,年增长率为56.5%。其中,AI服务器需求持续推动800G、1.6T,而传统服务器也升级规格,带动400G光模块需求。另据机构调查显示,2026年1.6T光模块需求量将大幅增加预计总出货量高达1100万台。主要驱动力来自于英伟达和谷歌的强劲收购,以及来自meta、微软和AWS的一些需求。光通信因其高带宽、低损耗、远距离等特点,逐渐成为内部和机柜一致性的主要选择,使得光模块成为数据中心协调的关键。 Trendforce指出,未来AI服务器之间的数据传输将需要大量的高速光收发模块。该模块负责将电信号转换为光信号,通过光纤发送,并将接收到的光信号转换回电信号。光收发模块、光通信和硅光子之间有什么关系?根据下图前两张原理图,可插拔光模块的传输速率目前市场上可以达到800g。下一阶段的光学引擎(Optical Engine,简称OE)可以安装在ASIC芯片封装周围。这就是所谓的板载光学器件(简称OBO),其传输能力最高可支持1.6T。目前,业界预计将走向“CPO”(co-packaged optics,共封装光学),即光学成分和ASIC可以共封装。通过technolo这个耻辱,可以实现3.2T以上,最高12.8T的交付速度;而最终的目标是实现“光I/o”(optical i/o),实现类似全光网络的技术,推动交付速度超过12.8t。如果你仔细观察上图,你会发现黄色方块状的光通信模块(以前是可插拔的)已经越来越接近ASIC。主要是为了缩短去电信号的传递路径,实现更高的带宽。硅光子的工艺流程是一个技术过程at 将光学成分融入芯片中。光通信需求显现,业界聚焦三服务器扩展架构。由于人工智能应用的爆发,对高速光通信的需求日益强烈。目前,服务器主要集中在两个扩展方向:scale up(垂直扩展)和scale out(水平扩展)。为了应对各种交付需求和技术挑战,Nvidia最近宣布了“scaleacross”的概念,为行业增加了一个新的思维方向。 Scale-Up主要用作机柜内的高速互连(上图中黄色部分)。送货距离一般在10米以内。由于延迟要求过低,内部主要使用“铜互连”,以防止光电转换带来的延迟和能量消耗。目前的解决方案主要是使用 Nvidia 的 Nvlink(closed架构)和AMD等公司主导的Ualyink(开放架构)呀。有趣的是,Nvidia今年推出了Nvlink Fusion,首次向外部芯片制造商开放NVLINK技术,将NVLINK从单一服务器节点扩展到整个机架级架构。不排除这是为了应对ulink的竞争。另一件值得关注的事情是,原本专注于scale-out的Broadcom正试图通过“以太网”进入scale-up市场。该公司最近推出了多款可用于纵向扩展并符合SUE(纵向扩展以太网)的芯片。大家可以关注Nvidia和Broadcom在这方面的竞争。 Scale-out是跨服务器的大规模并行操作(上图蓝色部分),用于解决高数据吞吐量的问题,实现无限扩展。它主要基于“光通信”。这网络互连的基础技术依赖于infiniband或以太网(Ethernet),这也将推动光通信模块市场的发展。 Infiniband和以太网可以分为两个阵营。前者受到Nvidia、微软等大厂青睐,后者则由博通、谷歌、AWS主导。说到 Infiniband,我们需要提到领先的 Mellanox 制造商,该公司于 2019 年被 Nvidia 收购,也是一家端到端以太网和 Infiniband 智能互连解决方案提供商。中国最近裁定英伟达针对此次收购违反了反垄断法。另一个担忧是,尽管Nvidia推出了很多infiniband产品,但它也推出了Nvidia Spectrum-X等针对以太网的相关产品,可以说是在吃同样的市场。作为另一大阵营,英特尔、AMD、博通等各大厂商于2023年7月齐聚成立超以太网联盟(UEC),合作开发超以太网增强的以太网交付架构,成为挑战Infiniband的力量之一。 Trendforce分析师褚玉超认为,规模化的数据传输市场驱动的光通信模式是未来数据传输的主战场。 Scale-across作为一种新兴的解决方案,Nvidia最近提出了“scale-across”的概念,即与数据中心的“长距离连接”。距离可以超过几公里,基于以太网推出的基于以太网的频谱-XGS-XGS将多个数据中心连接到该系列。 Spectrum-XGS 以太网将作为 COAI 映射中除了纵向扩展和横向扩展之外的第三列。它主要用于扩展spectrum-X以太网的终极性能和规模,并可以连接许多共享数据中心。据Nvidia介绍,除了提供横向扩展架构外,NVIDIA Spectrum-X以太网还连接整个集群,将许多共享数据中心相互关联,并将大量数据集快速传输至人工智能模型。它还可以协调数据中心 GPU 之间的通信。换句话说,该方案结合了横向扩展和跨域扩展,并且可以根据跨域距离调整负载平衡和动态调整算法,因此概念更类似于“规模地址”。英伟达创始人兼首席执行官黄仁勋表示,“在我们的纵向扩展和横向扩展之上,我们甚至增加了横向扩展,将数据中心连接到整个城市、国家甚至大陆,从而创建大型超级人工智能工厂。”如果我们看看当前的产业趋势,纵向扩展和横向扩展都是战场,我们可以看到英伟达和博通如何能够相互占领更多地盘。英伟达专注于数公里甚至上千公里跨数据中心的交付。那个AI芯片“(ASIC)。由于Nvidia GPU价格高昂,服务提供商(CSP)包括Google、MetA、Amaz之后,微软等都开发了自己的AI芯片,博通的ASIC能力成为这些公司的首选。除了自研芯片的竞争之外,另一个更关键的技术是“网络连接技术”,这也是博通和英伟达的第二个交集。首先是放大部分。在Nvlink和Cuda两大护城河的保护下,博通苦苦挣扎已久,终于在今年推出了最新的网络交换芯片Tomahawk Ultra。它有机会进入规模化市场,旨在挑战Nvidia Nvlink的主导地位。 Tomahawk Ultra是Broadcom.Plano of Net(简称SUE)推出的“纵向扩展以太网”,该产品也被认为是NVSWITCH的替代品。 Broadcom表示,该系列中的Tomahawk Ultra Monament一次可处理的芯片数量是NVLLINK交换机的四倍,并将在台积电的5nm工艺中给出。它不是值得一提的是,Broadcom虽然是Ualank联盟的成员,但也积极推广基于以太网的架构。因此,市场也十分关注博通与Ualink之间的竞争关系以及如何应对宿敌nvlink。为了对抗博通攻击,NVIDIA今年还推出了NVFusion解决方案,开放联发科、Marvell、Astera Labs等合作伙伴,通过NVLINK生态系统汇聚研究并创建定制AI芯片。外界认为,这是一次半开放的合作,将生态系统结合起来,也为更多的合作伙伴提供了一些定制的空间和机会。在横向扩展方面,这基本是由长期深耕以太网领域的Broadcom主导。最近推出的最新产品包括Tomahawk 6和Jericho4,以占领横向扩展的业务机会和更长的交付距离。 Nvidia推出多款Quantum Infiniband交换机产品nd Spectrum 以太网交换机平台可增强更多横向扩展产品。尽管Infiniband是开放架构,但产品生态系统仍然由Nvidia收购的Mellanox主导,这限制了客户的灵活性。根据博通的详细数据,三款产品分别采用两种不同的服务器扩展架构。对于更长距离的跨数据中心扩展规模的被告来说,博通还是英伟达谁将领先仍不确定。然而,Nvidia 是第一个为此概念推出 Spectrum-XG 的公司。该解决方案使用新的网络算法来有效地将数据传输到站点之间更远的距离。它还可以用作现有纵向扩展和横向扩展架构的补充解决方案。至于Broadcom的Jericho4,也符合规模被告的概念。博通指出,Tomahawk系列芯片可以将机柜连接到该系列中的单个数据中心,连接距离通常不超过一公里更远(约0.6英里),而Jerico4设备可以处理超过100公里的跨机房连接,保持了上一代产品的四倍。那么Nvidia和Broadcom的CPO有哪些解决方案呢?随着传送网战场的继续,相信光网络的竞争将会更加激烈。 Nvidia和Broadcom都在寻找CPO光通信的新解决方案,而台积电和格罗方德正在积极开发CPO的工艺和解决方案。 Nvidia的做法从系统架构开始,将光学互连视为SOCMGA点的一部分,而不是插件模块,今年GTC正式发布了Quantum-X Photonics Infiniband Switch和spectrum-x Photonics以太网交换机。前者将于年底推出,后者将于2026年发布。两个平台均采用台积电coupe平台,集成65纳米Pho通过 soic-x 封装技术的 tonic 集成电路 (PIC) 和电子集成电路 (EIC)。这种做法的出发点是强调整合自有平台,提升整体效率和扩大规模。 Broadcom的做法侧重于提供全面的解决方案,专注于大规模供应链运营,为第三方客户提供完整的模块化解决方案,并帮助客户实施其应用。博通还表示,公司在CPO领域的成功基于半导体集成和光学技术的深厚能力。 Broadcom目前正在推出第三代200G/Lane CPO来抢占市场。博通还表示,其CPO产品采用3D芯片堆叠架构,PIC也采用65nm,EIC则采用7nm工艺。从下图可以看出,光收发模块由以下基本成分组成,Tullelaser光源(激光由于涉及到电光转换,因此也可以说是决定单通道传输速度的关键。对于主要的光调制器,Nvidia选择了MRM(微环调制器)。由于MRM尺寸较小,很容易受到误差和温度的影响,这也将是引入MRM的挑战之一。至于博通则选择使用更为成熟的MZM调制器(mach-zehder调制器),同时布局了MRM技术。已经通过了3纳米工艺的考验,并继续以堆叠芯片的方式引领CPO开发。目前,随着AI Inference的不断拓展,市场焦点逐渐从“算力竞争”转向“数据传递速度”。如果是Broadcom推动的neTWORK和技术转移,或者是NVIDIA一直以来的端到端解决方案,谁能最先突破交付和延迟效率的限制将有机会引领下一波人工智能竞争。
特别声明:以上内容(如有则包括照片或视频)由“网易号”自媒体平台用户上传发布。本平台仅提供信息存储服务。
注:以上内容(包括照片和视频)由Nete ASEhao用户上传发布,该平台为社交媒体平台,仅提供信息存储服务。
文章|能够率先突破交付和延迟效率极限的半导体行业内部人士,将有机会引领下一波人工智能竞争浪潮。在人工智能(AI)和机器研究的推动下,全球数据流量急剧增加。目前,数据中心服务器和交换机之间的连接正在从200G、400G快速走向800G、1.6T,甚至还可以进入3.2T时代。市场研究机构预测,2023年400G以上光收发模块全球传输量为640万台,2024年约为2040万台,预计2025年将超过3190万台,年增长率为56.5%。其中,AI服务器需求持续推动800G、1.6T,而传统服务器也升级规格,带动400G光模块需求。另据机构调查显示,2026年1.6T光模块需求量将大幅增加预计总出货量高达1100万台。主要驱动力来自于英伟达和谷歌的强劲收购,以及来自meta、微软和AWS的一些需求。光通信因其高带宽、低损耗、远距离等特点,逐渐成为内部和机柜一致性的主要选择,使得光模块成为数据中心协调的关键。 Trendforce指出,未来AI服务器之间的数据传输将需要大量的高速光收发模块。该模块负责将电信号转换为光信号,通过光纤发送,并将接收到的光信号转换回电信号。光收发模块、光通信和硅光子之间有什么关系?根据下图前两张原理图,可插拔光模块的传输速率目前市场上可以达到800g。下一阶段的光学引擎(Optical Engine,简称OE)可以安装在ASIC芯片封装周围。这就是所谓的板载光学器件(简称OBO),其传输能力最高可支持1.6T。目前,业界预计将走向“CPO”(co-packaged optics,共封装光学),即光学成分和ASIC可以共封装。通过technolo这个耻辱,可以实现3.2T以上,最高12.8T的交付速度;而最终的目标是实现“光I/o”(optical i/o),实现类似全光网络的技术,推动交付速度超过12.8t。如果你仔细观察上图,你会发现黄色方块状的光通信模块(以前是可插拔的)已经越来越接近ASIC。主要是为了缩短去电信号的传递路径,实现更高的带宽。硅光子的工艺流程是一个技术过程at 将光学成分融入芯片中。光通信需求显现,业界聚焦三服务器扩展架构。由于人工智能应用的爆发,对高速光通信的需求日益强烈。目前,服务器主要集中在两个扩展方向:scale up(垂直扩展)和scale out(水平扩展)。为了应对各种交付需求和技术挑战,Nvidia最近宣布了“scaleacross”的概念,为行业增加了一个新的思维方向。 Scale-Up主要用作机柜内的高速互连(上图中黄色部分)。送货距离一般在10米以内。由于延迟要求过低,内部主要使用“铜互连”,以防止光电转换带来的延迟和能量消耗。目前的解决方案主要是使用 Nvidia 的 Nvlink(closed架构)和AMD等公司主导的Ualyink(开放架构)呀。有趣的是,Nvidia今年推出了Nvlink Fusion,首次向外部芯片制造商开放NVLINK技术,将NVLINK从单一服务器节点扩展到整个机架级架构。不排除这是为了应对ulink的竞争。另一件值得关注的事情是,原本专注于scale-out的Broadcom正试图通过“以太网”进入scale-up市场。该公司最近推出了多款可用于纵向扩展并符合SUE(纵向扩展以太网)的芯片。大家可以关注Nvidia和Broadcom在这方面的竞争。 Scale-out是跨服务器的大规模并行操作(上图蓝色部分),用于解决高数据吞吐量的问题,实现无限扩展。它主要基于“光通信”。这网络互连的基础技术依赖于infiniband或以太网(Ethernet),这也将推动光通信模块市场的发展。 Infiniband和以太网可以分为两个阵营。前者受到Nvidia、微软等大厂青睐,后者则由博通、谷歌、AWS主导。说到 Infiniband,我们需要提到领先的 Mellanox 制造商,该公司于 2019 年被 Nvidia 收购,也是一家端到端以太网和 Infiniband 智能互连解决方案提供商。中国最近裁定英伟达针对此次收购违反了反垄断法。另一个担忧是,尽管Nvidia推出了很多infiniband产品,但它也推出了Nvidia Spectrum-X等针对以太网的相关产品,可以说是在吃同样的市场。作为另一大阵营,英特尔、AMD、博通等各大厂商于2023年7月齐聚成立超以太网联盟(UEC),合作开发超以太网增强的以太网交付架构,成为挑战Infiniband的力量之一。 Trendforce分析师褚玉超认为,规模化的数据传输市场驱动的光通信模式是未来数据传输的主战场。 Scale-across作为一种新兴的解决方案,Nvidia最近提出了“scale-across”的概念,即与数据中心的“长距离连接”。距离可以超过几公里,基于以太网推出的基于以太网的频谱-XGS-XGS将多个数据中心连接到该系列。 Spectrum-XGS 以太网将作为 COAI 映射中除了纵向扩展和横向扩展之外的第三列。它主要用于扩展spectrum-X以太网的终极性能和规模,并可以连接许多共享数据中心。据Nvidia介绍,除了提供横向扩展架构外,NVIDIA Spectrum-X以太网还连接整个集群,将许多共享数据中心相互关联,并将大量数据集快速传输至人工智能模型。它还可以协调数据中心 GPU 之间的通信。换句话说,该方案结合了横向扩展和跨域扩展,并且可以根据跨域距离调整负载平衡和动态调整算法,因此概念更类似于“规模地址”。英伟达创始人兼首席执行官黄仁勋表示,“在我们的纵向扩展和横向扩展之上,我们甚至增加了横向扩展,将数据中心连接到整个城市、国家甚至大陆,从而创建大型超级人工智能工厂。”如果我们看看当前的产业趋势,纵向扩展和横向扩展都是战场,我们可以看到英伟达和博通如何能够相互占领更多地盘。英伟达专注于数公里甚至上千公里跨数据中心的交付。那个AI芯片“(ASIC)。由于Nvidia GPU价格高昂,服务提供商(CSP)包括Google、MetA、Amaz之后,微软等都开发了自己的AI芯片,博通的ASIC能力成为这些公司的首选。除了自研芯片的竞争之外,另一个更关键的技术是“网络连接技术”,这也是博通和英伟达的第二个交集。首先是放大部分。在Nvlink和Cuda两大护城河的保护下,博通苦苦挣扎已久,终于在今年推出了最新的网络交换芯片Tomahawk Ultra。它有机会进入规模化市场,旨在挑战Nvidia Nvlink的主导地位。 Tomahawk Ultra是Broadcom.Plano of Net(简称SUE)推出的“纵向扩展以太网”,该产品也被认为是NVSWITCH的替代品。 Broadcom表示,该系列中的Tomahawk Ultra Monament一次可处理的芯片数量是NVLLINK交换机的四倍,并将在台积电的5nm工艺中给出。它不是值得一提的是,Broadcom虽然是Ualank联盟的成员,但也积极推广基于以太网的架构。因此,市场也十分关注博通与Ualink之间的竞争关系以及如何应对宿敌nvlink。为了对抗博通攻击,NVIDIA今年还推出了NVFusion解决方案,开放联发科、Marvell、Astera Labs等合作伙伴,通过NVLINK生态系统汇聚研究并创建定制AI芯片。外界认为,这是一次半开放的合作,将生态系统结合起来,也为更多的合作伙伴提供了一些定制的空间和机会。在横向扩展方面,这基本是由长期深耕以太网领域的Broadcom主导。最近推出的最新产品包括Tomahawk 6和Jericho4,以占领横向扩展的业务机会和更长的交付距离。 Nvidia推出多款Quantum Infiniband交换机产品nd Spectrum 以太网交换机平台可增强更多横向扩展产品。尽管Infiniband是开放架构,但产品生态系统仍然由Nvidia收购的Mellanox主导,这限制了客户的灵活性。根据博通的详细数据,三款产品分别采用两种不同的服务器扩展架构。对于更长距离的跨数据中心扩展规模的被告来说,博通还是英伟达谁将领先仍不确定。然而,Nvidia 是第一个为此概念推出 Spectrum-XG 的公司。该解决方案使用新的网络算法来有效地将数据传输到站点之间更远的距离。它还可以用作现有纵向扩展和横向扩展架构的补充解决方案。至于Broadcom的Jericho4,也符合规模被告的概念。博通指出,Tomahawk系列芯片可以将机柜连接到该系列中的单个数据中心,连接距离通常不超过一公里更远(约0.6英里),而Jerico4设备可以处理超过100公里的跨机房连接,保持了上一代产品的四倍。那么Nvidia和Broadcom的CPO有哪些解决方案呢?随着传送网战场的继续,相信光网络的竞争将会更加激烈。 Nvidia和Broadcom都在寻找CPO光通信的新解决方案,而台积电和格罗方德正在积极开发CPO的工艺和解决方案。 Nvidia的做法从系统架构开始,将光学互连视为SOCMGA点的一部分,而不是插件模块,今年GTC正式发布了Quantum-X Photonics Infiniband Switch和spectrum-x Photonics以太网交换机。前者将于年底推出,后者将于2026年发布。两个平台均采用台积电coupe平台,集成65纳米Pho通过 soic-x 封装技术的 tonic 集成电路 (PIC) 和电子集成电路 (EIC)。这种做法的出发点是强调整合自有平台,提升整体效率和扩大规模。 Broadcom的做法侧重于提供全面的解决方案,专注于大规模供应链运营,为第三方客户提供完整的模块化解决方案,并帮助客户实施其应用。博通还表示,公司在CPO领域的成功基于半导体集成和光学技术的深厚能力。 Broadcom目前正在推出第三代200G/Lane CPO来抢占市场。博通还表示,其CPO产品采用3D芯片堆叠架构,PIC也采用65nm,EIC则采用7nm工艺。从下图可以看出,光收发模块由以下基本成分组成,Tullelaser光源(激光由于涉及到电光转换,因此也可以说是决定单通道传输速度的关键。对于主要的光调制器,Nvidia选择了MRM(微环调制器)。由于MRM尺寸较小,很容易受到误差和温度的影响,这也将是引入MRM的挑战之一。至于博通则选择使用更为成熟的MZM调制器(mach-zehder调制器),同时布局了MRM技术。已经通过了3纳米工艺的考验,并继续以堆叠芯片的方式引领CPO开发。目前,随着AI Inference的不断拓展,市场焦点逐渐从“算力竞争”转向“数据传递速度”。如果是Broadcom推动的neTWORK和技术转移,或者是NVIDIA一直以来的端到端解决方案,谁能最先突破交付和延迟效率的限制将有机会引领下一波人工智能竞争。
特别声明:以上内容(如有则包括照片或视频)由“网易号”自媒体平台用户上传发布。本平台仅提供信息存储服务。
注:以上内容(包括照片和视频)由Nete ASEhao用户上传发布,该平台为社交媒体平台,仅提供信息存储服务。 上一篇:从人工智能调控体系到长寿密码破解,同济大学
下一篇:没有了
下一篇:没有了

